
外国語でのコミュニケーションにおいて、翻訳の「タイムラグ」や「機械的な音声」にストレスを感じたことはありませんか?
2026年6月9日、Googleはリアルタイムの多言語会話を劇的に自然にする新しい音声モデル「Gemini 3.5 Live Translate」を発表しました。従来の翻訳システムが抱えていた遅延や不自然さを根本から解決するこの技術は、個人の旅行からグローバル企業のビジネス会議まで、あらゆるコミュニケーションのあり方を変えようとしています。

本記事では、Gemini 3.5 Live Translateの革新的な仕組みから、具体的な利用シーン、他社AIモデルとの比較、そして今後の展望までを分かりやすく徹底解説します。
Gemini 3.5 Live Translateとは?従来の翻訳との決定的な違い
これまでの機械通訳は、「音声認識(テキスト化)」→「機械翻訳」→「音声合成」という複数の段階を踏む必要がありました。この方式では、どうしても数秒から十数秒の遅延が発生し、またテキスト化の過程で話者の「感情」や「声のトーン」が失われてしまうという大きな欠点がありました。
今回登場したGemini 3.5 Live Translateは、この仕組みを根本から覆しました。

最大の特長は、音声をテキストに変換することなく、直接的な音声対音声(Speech-to-Speech)で処理を行う点にあります。話者が発言を終えるのを待つのではなく、継続的に音声を聞き取り、翻訳し、ほぼ同時に発話する「ストリーミング処理」を実現しました。
これにより、会話の遅延はわずか数秒に短縮され、人間同士の自然な会話ペースを再現することが可能になったのです。日本語を含む70以上の言語を自動検出する能力を備えています。
圧倒的な自然さを生み出す技術的特徴
Gemini 3.5 Live Translateが優れているのは、単に翻訳スピードが速いだけではありません。コミュニケーションの質を高めるための高度な技術が組み込まれています。
感情とイントネーション(韻律)の保持
言語の壁を越えるには、言葉の意味だけでなく「どのように話しているか」が重要です。Gemini 3.5 Live Translateは、元の話者のイントネーション、ペース、ピッチを検出し、それをターゲット言語の音声で再現します。
例えば、語尾を上げる疑問文のイントネーションや、早口で伝えられる緊急性の高いトーンなどは、翻訳された音声にもそのまま反映されます。これにより、機械的ではない、感情のこもったコミュニケーションが実現します。
巨大なコンテキストウィンドウによる文脈理解
本モデルは、Googleのネイティブなマルチモーダル推論モデルである「Gemini 3 Pro」のアーキテクチャを基盤としています。
継続的なオーディオストリームに対して最大128,000トークンの入力コンテキストウィンドウを利用できるため、長時間の会話でも文脈を失うことなく、複雑な言語のニュアンスを正確に解釈し続けることが可能です。
ノイズに強いストリーミング生成
バックグラウンドノイズや、複数人の発言が重なるような環境下でも効果的に機能するように設計されています。単に言葉の区切りを待つのではなく、言語の軌跡を予測しながら処理を行うため、不自然な沈黙や途切れのない流暢な音声出力が行われます。
具体的な利用シーン:Googleエコシステムへの統合
Gemini 3.5 Live Translateは、私たちが普段使っているGoogleのサービスに順次統合されています。
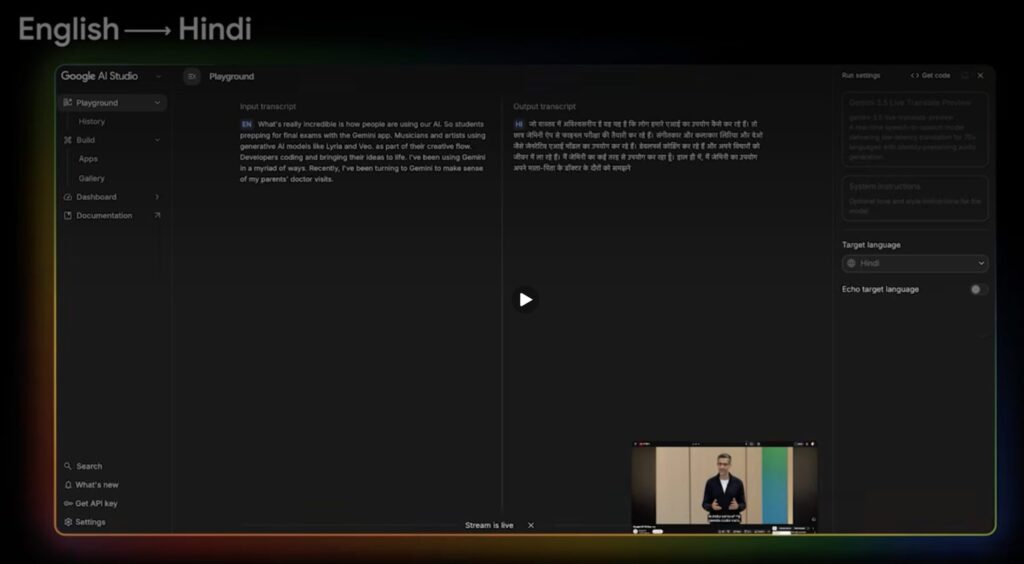
Google翻訳アプリの「リスニングモード」
AndroidおよびiOS向けのGoogle翻訳アプリに、新たに「Live translate」ボタンが追加されました。手動で言語を選択することなく、ハンズフリーの同時通訳体験が可能になります。
特に画期的なのが、Android版アプリに実装された「リスニングモード」です。イヤホンがない状況でも、スマートフォンを耳に当てるだけで、外部マイクが周囲の外国語を拾い、ほぼリアルタイムで翻訳された音声を直接受話口(イヤピース)から聞くことができます。画面を交互に見せ合う従来の不自然な動作から解放されます。
Google Meetのエンタープライズ対応が劇的進化
ビジネスシーンでは、Google Meetの通訳機能が大幅に拡張されました。

従来はサポート言語が5言語に限られ、必ず「英語」を介する必要がありましたが、Gemini 3.5 Live Translateの統合により、以下の機能強化が図られています。
- サポート言語が70言語以上に拡大
- 英語を介さず、任意の2言語間で直接翻訳が可能(2,000以上の言語ペアに対応)
- 字幕ベースではなく、継続的なストリーミング音声生成へ
※2026年6月現在、一部のGoogle Workspaceエンタープライズクライアント向けにプライベートプレビューとして提供されており、年内に一般提供が予定されています。
開発者向けAPIの公開と破壊的な価格設定
Googleは業界全体への普及を狙い、開発者向けに「Gemini Live API」を公開しました。
開発プラットフォームとの連携
超低遅延での音声ストリーミングを実現するため、GoogleはAgoraやLiveKitといったリアルタイムメディアストリーミングインフラストラクチャと提携しています。特に、Fishjamが提供する「MoQ(Media over QUIC)」プロトコルとの組み合わせにより、パケット損失やバッファリング遅延をほぼゼロに抑えたメディア配信が可能になっています。

東南アジアの配車サービスGrabなどの企業では、すでにドライバーと外国人旅行者間の多言語通話の最適化にこの技術のテスト導入を開始しています。
コスト破壊をもたらす料金体系
APIの価格設定は、従来の通訳サービスに衝撃を与える水準です。オーディオ処理のコストは、アクティブなバイリンガル通信1分あたり約0.0368ドル(有料ティアの場合)に設定されています。
これにより、継続的な双方向翻訳を伴う60分間のエンタープライズ会議であっても、計算コストはわずか2.50ドル未満に抑えられます。これは人間の労働力に依存していたローカリゼーション業界にとって、大きなパラダイムシフトとなります。
安全性への配慮と残された技術的課題
高度な音声合成技術の普及に伴う「ディープフェイク」などの悪用リスクに対し、Googleは厳重な対策を講じています。
電子透かし技術「SynthID」の義務化
Gemini 3.5 Live Translateで生成されたすべての音声には、「SynthID」と呼ばれる音響ウォーターマーク(電子透かし)が直接埋め込まれます。これは人間の耳には聞こえず、音声の圧縮や速度変更といった操作を行っても検出可能であり、AI生成音声の悪用を防ぐ強力な抑止力となります。
認識しておくべき課題
画期的な技術である一方、現時点ではいくつかの技術的限界も報告されています。
- ボイスドリフト現象: 長時間の会話や沈黙の後に、生成される音声のトーンが元の話者から徐々に離れてしまう現象。
- 複数話者の混同: 高速で言葉を交わす環境では、音声の性別が切り替わったり、混同が生じることがある。
- エッジケースでの精度低下: 強いアクセントや、言語を急速に切り替えるコードスイッチングの場面では、言語の検出・翻訳精度が低下する傾向がある。
競合環境:OpenAIやAppleとの比較
リアルタイム音声AIの市場では、激しい競争が繰り広げられています。
- OpenAI(GPT-4o Realtime API): Geminiと同様に音声対音声のアーキテクチャを採用しています。ヒンディー語など一部の言語ではGPT-4oが意味の保持力で優れる一方、特定のドラヴィダ語族などではGeminiが優位に立つなど、言語ごとの最適化で一進一退の攻防が続いています。
- Apple: 自社のハードウェアエコシステム(iOS)に統合された「ライブ翻訳」を提供しています。言語数ではGoogleに遅れをとるものの、デバイスネイティブな統合という強みを持っています。Googleが「リスニングモード」などの新体験を急ピッチで展開しているのは、これに対抗する狙いがあります。
まとめ:多言語コミュニケーションの壁が消える日
Googleの「Gemini 3.5 Live Translate」は、単なる翻訳ツールのアップデートではなく、グローバルコミュニケーションにおけるインフラストラクチャの進化と言えます。
数秒の遅延で感情までをも伝えるこの技術は、ビジネスの交渉から異文化間の日常的なやり取りまで、言葉の壁を意識させない世界を現実のものにしつつあります。今後のアップデートによる精度のさらなる向上と、幅広いサービスへの統合に大きな期待が寄せられています。
{kind=link}